
長音記号とReplace string
Page 1 of 2 • 1, 2 ![]()

長音記号とReplace string
![]() by hosaka 2018-04-17, 11:10 am
by hosaka 2018-04-17, 11:10 am
$target_t:=Replace string($target_t;"ー";"-")
v12まではこれで変換できていたのですが、v16では変換しません。
$target_t:=Replace string($target_t;"ー";"-";*)
として文字コードに基づいて評価してみたところちゃんと変換されました。
なんなんでしょうね。

hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by miyako 2018-04-20, 6:44 am
by miyako 2018-04-20, 6:44 am
例:
ホイール
ホイール
ほいーる
ホイル
ホイル
ほいる
「ほいーる」でクエリした場合・・・
v15:3件が合致
v16:2件が合致
半角カタカナの長音記号は「ハイフン」と等価であり,全角の長音記号と等価ではないことがわかります。
動作が変わったことに変わりはありませんが,これは4DがUnicodeの仕様に従っているためであり,予期される動作です。なお,4Dのストラクチャファイルとデータファイルには,インデックス作成時のICUおよびMeCabのバージョン番号を記録されており,バージョンの不一致が検出された場合(たとえばv16アップグレード直後),自動的にインデックスが再構築されるようになっています。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by hosaka 2018-04-20, 8:56 am
by hosaka 2018-04-20, 8:56 am
miyako wrote:
半角カタカナの長音記号は「ハイフン」と等価であり,全角の長音記号と等価ではないことがわかります。
この説明だと、これは動作しないといけないと思うのですが?
$target_t:=Replace string($target_t;"ー";"-")
等価でないので入れ替わらないと正しい動作だと言えません。実際には入れ替わらなかったので問題になっていました。
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by miyako 2018-04-20, 9:37 am
by miyako 2018-04-20, 9:37 am
では,別の理由かもしれません。
歴史的に,Unicodeでは日本語の長音記号を「文字ではない。発音記号の一種。」とみなし,
単独の文字としては扱わない風潮があります。(学者が決めていることなので・・・)
v11(ICU 3.6/3.8)の初期は「あー=ああ」というルールがあり,「ー」は単独の文字ではなく,直前の文字が「あ行」であれば「あ」,「い行」ではあれば「い」,の「音」を伸ばす記号という理由で,「ー」を検索することができませんでした。
その後,Unicodeのフラグ設定「旧バージョン互換の文字列比較」でこれを回避したわけですが,最新のICUでは,この設定が無視される,あるいは部分的にしか適用されないようです。Replace stringの*オプションは,ICUを使用しないモードであり,まさにこのようなときに効果を発揮します。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by hosaka 2018-04-20, 9:46 am
by hosaka 2018-04-20, 9:46 am
それではこの動作はバグと言うことでよいのでしょうか?miyako wrote:$target_t:=Replace string($target_t;"全角長音記号";"半角長音記号")
では,別の理由かもしれません。
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by miyako 2018-04-20, 9:52 am
by miyako 2018-04-20, 9:52 am
15R5(ICUをアップデートしたバージョン)からの変化であり,Unicodeコンソーシアムの標準に準拠しているICUの振る舞いによるものであるため,4Dのバグではないということです。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by hosaka 2018-04-20, 10:28 am
by hosaka 2018-04-20, 10:28 am
ACI0096993これだけでは、Standard Behaviourの理由がよくわからないのですが...miyako wrote:ACI0096993(2017年7月に報告)は,Standard Behaviour(設計上,予期される動作)となっています。
15R5(ICUをアップデートしたバージョン)からの変化であり,Unicodeコンソーシアムの標準に準拠しているICUの振る舞いによるものであるため,4Dのバグではないということです。
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by miyako 2018-04-22, 7:05 pm
by miyako 2018-04-22, 7:05 pm
4D側には何も手を加えておらず,ICUライブラリのバージョンを更新したところ,このような振る舞いになったので,これは4Dのバグではない,ということでした。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by 内山 高志 2018-04-23, 9:18 am
by 内山 高志 2018-04-23, 9:18 am
>4D側には何も手を加えておらず,ICUライブラリのバージョンを更新したところ,このような振る舞いになったので,これは4Dのバグではない,ということでした。
まあ、そういう言い方もできるし、4Dのバグだー!!と大騒ぎするつもりもないのですが、システムを使用されているエンドユーザさんとしては
「どっちでもいいから、元に戻して」
だと思うのです。
我々はそれに応えなければならないのです。
申し訳ないのですが、全部を書き換えるのはしんどすぎるので、「半角のハイフンを全角の長音記号と同一と見なす。」(? hosakaさんの不具合は逆かな?)オプションを新たに作って頂くのが、分析が仕事の学者ではなく、製品をお客様に購入して頂くメーカーさんのより良い姿勢ではないかな、思うのです。
バグではないですが、強い修正要望です。
内山 高志- 投稿数 : 37
登録日 : 2016/07/13
Re: 長音記号とReplace string
![]() by miyako 2018-04-23, 10:48 am
by miyako 2018-04-23, 10:48 am
試しに,v16のICUをv15のものと入れ替えたところ,

起動時にエラーが表示されました。
それは,4Dが内部的にバージョンチェックを実行しているからなのかもしれませんが,いずれにしても,オープンソースライブラリは,バージョンをメンテナンスしてゆくことが「メーカーさん」としての責任だと考えられていますし,古いバージョンで止めることはできないと思います。加えて,ICU(これを使用しているアプリケーションは非常に多いはずです)の日本語デベロッパーコミュニティの間でこの振る舞いが問題視されているのであれば,より新しいICUで「修正」されるかもしれません。現状,長音記号を単独の文字(記号)として扱うのか,そうしないのかを決めているのは4Dではなく,Unicodeですから,Unicode側でそのようなオプションが提供されていない限り,「元に戻す」ためには,ICUをオーバーライドするような「人為的バグ」を4D側で開発しなければなりません(この場合,「バグ」とは文書化された仕様に対する違反を指します)。しかし,それはメーカーとしてできないことではないでしょうか。
むしろ,前バージョンと同じ振る舞いを再現するICUの公式な設定パラメーターがほんとうに撤廃されたのか,代替となる手段はないのか,その点を徹底的に調査したいと考えています。その点で,有用な情報をお持ちであれば,是非,参考にさせていただきたい所存です。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by 内山 高志 2018-04-23, 11:37 am
by 内山 高志 2018-04-23, 11:37 am
まず、最初に、メーカー批判・攻撃ととらえられたのであれば、申し訳ないです。
そういう意図ではないです。
「元に戻して」はエンドユーザさんの意見として、「4Dを最終的に使う方から見て以前と同じ振る舞いをする様にして」
と言う意味で、我々技術屋や、メーカーさんとして、「以前と同じライブラリにする」と言う意味では、もちろんないですよ。
>いずれにしても,オープンソースライブラリは,バージョンをメンテナンスしてゆくことが「メーカーさん」としての責任だと考えられていますし,古いバージョンで止めることはできないと思います。
その通りだと思いますし、「古いバージョンで止めるべきではないと思います。
>...Unicodeですから,Unicode側でそのようなオプションが提供されていない限り,「元に戻す」ためには,ICUをオーバーライドするような「人為的バグ」を4D側で開発しなければなりません(この場合,「バグ」とは文書化された仕様に対する違反を指します)。しかし,それはメーカーとしてできないことではないでしょうか。
なるほど。
不勉強で申し訳ないのですが、ICUを使う以上、その振る舞いを変換テーブルなどを使って勝手に変えてはいけない、と言う規約があるのでしょうか。
もしそうであるなら、仕方ないな。と思いますし、ユーザさんにもその様に説明します。
4Dの仕様が変わっちゃったので(ICUと言えども、ユーザさんから見たら4Dの一部ですし、
専門的な事を話すと、「煙に巻こうとしている」とか思われちゃうんで)バージョンアップ費に
対策費乗せますね。
と言う事ですものね。
ただ、そんな厳密な話ではない。と言う事であれば、楽をしたいな。と言うことです。
>むしろ,前バージョンと同じ振る舞いを再現するICUの公式な設定パラメーターがほんとうに撤廃されたのか,代替となる手段はないのか,その点を徹底的に調査したいと考えています。
はい。正にお願いしたいのはこの点です。
その上で、
ICUとしてはどうしようもない。そうなっちゃった。と言う事であれば、
次は4Dさんどうされます?オプションで元と同じ振る舞いができる様にします?となり、
ICUの規約上かえられないんだよねー。とか リソース目一杯だから今は無理、 ということであれば、
ICUを使用しないと言うオプションもある事だし、デベロッパーががんばるか。
と言う、いつものお話なんですよね。
いくつも開発手段のある中で、あえて、4Dを選んだのはこちらですし、4Dを選ぶ以上、4D社が提供する中で
開発する必要がある事は理解しています。
4D社のリソースに限りがあるのは重々承知していますので、無理を言うつもりはないですから、
いつも「ちょっといまは難しい。ごめん。」であれば、こっちでがんばるか。と考えて、30年近くお付き合い
させてもらってきてたわけです。
でも、今回の件は、「半角でも全角でもどっちもOK」という4Dの伝統的なメリットがなくなっちゃうとするならば惜しいな。
何とかならかないかな、と思った次第です。
学者さんがどう考えようが、ハイフンは半角の長音として使ってきたわけなので。
なので、「強い希望」とさせてもらいました。
上記の通り、ICUを使わないと言うオプションもある事だし、難しいならばいつも通りこっちががんばりますよ。
4D Japanの方は皆さんお忙しいですから、限界を超えた無理されないでくださいね。
内山 高志- 投稿数 : 37
登録日 : 2016/07/13
Re: 長音記号とReplace string
![]() by miyako 2018-04-23, 12:56 pm
by miyako 2018-04-23, 12:56 pm
ICUのオプションについて
http://demo.icu-project.org/icu-bin/locexp?_=ja&d_=en&x=col&collation=traditional
こちらのURLを開き,Sourceという左側にエリアに
ケース
ケース
ケエス
をペーストし,「Sort」ボタンをクリックしてみてください。
ケース
ケース
ケエス
と並び順が表示されます。
ポップアップOptions一番上を「L2」に変更し,もう一度,「Sort」ボタンをクリックしてみてください。
ケース
ケース・ケエス
と並び順が表示されます。
これが,現在,4Dに搭載されているICUにおける,クエリの判定ルールです。
v15まで採用していたICUのバージョンは,これとは違う結果を返しました。
注記:L2は並び替えのルール,L3はクエリ(文字列比較)のルールに相当します。
http://demo.icu-project.org/icu-bin/locexp?_=ja&d_=en&x=col&collation=search
今度は,こちらのURLを開き,同じことをしてみてください。
L2で,
ケース・ケース
ケエス
と並び順が表示されます。
つまり,v11-v15まで,非Unicodeに似た振る舞いを提供するオプションである「traditional」を4Dは指定していたわけですが,最新のICUでは,少なくとも長音記号に関しては,Unicode標準に準拠するようになり,逆に「search」モードのほうが,少なくとも長音記号に関しては,非Unicodeに似た振る舞いを提供するになったということです。では,「search」モードにすれば良いではないか,と思われるかもしれません。私もそう思いますが,他に望ましくない違いがあるかもしれませんので,慎重に対応を決定しなければならない事情があります。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by hosaka 2018-04-24, 9:44 am
by hosaka 2018-04-24, 9:44 am
v16でテストしてみると、
If ("ー"="-")
ALERT("一致")
Else
ALERT("不一致")
End if
は不一致と表示されます。説明からすると非Unicode(L3)の振る舞いだと考えられます。
$target_t:=Replace string($target_t;"ー";"-")
では変換されませんので、Unicode標準(L2)の振る舞いをしていると考えれれます。
内部の処理がわからないのですがReplace stringは比較して置き換える処理なので、
L2からL3に変更する方が矛盾がない様に思います。
ちなみに、
$word_t:="ケース"
$match_b:=Match regex("-";$word_t;1)
ではマッチしないのでL3の振る舞いをしている様です。
私的には今回の問題はバージョンが上がったことのアナウンスがなかった事(ICUの仕様から問題が発生する可能性があった事)、
それにより動作が違う事が大分前にわかっていた(ACI0096993 2017年7月)のにアナウンスすらなかった事は問題だと思う。
あと報告者以外がACI0096993がどの様な報告内容だったのかも未だにわからないし、内容を閲覧する方法がない様に思います。
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by miyako 2018-04-25, 7:04 am
by miyako 2018-04-25, 7:04 am
L1, L2, L3は,
L1: もっともゆるい
L2: アクセント記号で区別する(濁点・半濁点が含まれる)
L3: 大文字と小文字の違いを区別する
L4: 「ハイフンとスペースを無視する」を無視する/ひらがなとカタカナを区別する
L5: 文字コードレベルで区別する
といった具合に,レベルがあがるごとにより「厳格な」比較基準を意味します。
データベースの言語が日本語の場合,「=/#」演算子はL2となります。他言語ではL1です。英語モードは「a」と「á」を区別しないのが望ましく,日本語モードは「た」と「だ」を区別するのが望ましい,という考えが背景にあります。
L3で区別する大文字と小文字とは,アルファベットのAとaの違いに加え,日本語の「ちいさい字」と「おおきい字」の区別も含まれます。4Dで,「きゅう」と「きゆう」が区別されないのは,L3よりもゆるい指定をしているためです。
L4は,ignore punctuationというオプション(ICUのデフォルトはoff)と併用します。このオプションが指定された場合,L3まで,black-bird=blackbird,black birds=blackbirds,"きれいな 花"="きれいな花"となりますが,L4は,オプションが指定されていても,ハイフンやスペースを無視しません。
加えて,L4は,ひらがなとカタカナを区別するためにも使用されます。4Dで,「か」と「カ」が区別されないのは,L4よりもゆるい指定をしているためです。
半角と全角の違いは,L5(文字コードレベル)を指定しない限り,原則的に同一視されます。
Lxとは別に,言語特有のルール(sort order)があります。
長音記号や半角と全角の扱いには,Lxだけでなく,sort orderも関係しています。本来,長音記号はL3で区別されますが,L2であっても,sort orderで以下のとおりになります。
sort order=default, standard, traditional
「ー」=「ー」
「あー」=「ああ」=「 アア」=「アア」
「カー」#「カー」
sort order=search
「ー」=「ー」
「あー」#「ああ」
「ああ」=「 アア」=「アア」
「カー」=「カー」
今回,問題視しているのは,ICU5でtraditionalの振る舞いがstandard/defaultと同じになった(長音記号を単独の文字として扱わないようになった)と思われる点です。以前は,searchのような振る舞いでした。なお,上述した「ー」は,いずれも,半角の長音記号(U+FF70)です。長音記号と半角のハイフン(U+002D)と同一視するようなルールはないと思われます。
ASSERT ("ー"="-";"不一致")
とのことですが,これはv15でもそうであり,
ASSERT("ー"="ー";"不一致")
としなければなりません。
似ていますが,前者はハイフン,後者は半角の長音記号です。
「L2からL3に変更する方が矛盾がない」とのことですが,L3を指定するということは,
sort order=default, standard, traditional
「ー」#「ー」
「あー」#「ああ」
「ああ」=「 アア」=「アア」
「カー」#「カー」
sort order=search
「ー」#「ー」#「あー」#「ああ」#「ああ」#「 アア」#「アア」#「カー」#「カー」
となり,劇的に振る舞いが変わってしまいます。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by hosaka 2018-04-25, 10:49 am
by hosaka 2018-04-25, 10:49 am
L3に変更した場合に劇的に振る舞いがかわるとの事で例をあげていただいているのですが
長音記号は除外して、「ああ」と「アア」と「アア」や「カー」と「カー」が一致しなくなると言う事ですね。
ICUの互換性は危惧されているようですが、Replace stringとしての互換性は危惧されないのが疑問です。
4Dをバージョンアップして互換性が失われているのにこれは矛盾しているのではないでしょうか。
内山さんのご指摘どおり、4Dとしての互換性を維持するために例外処理を追加するという選択肢を排除している様に感じます。
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by hosaka 2018-04-25, 12:50 pm
by hosaka 2018-04-25, 12:50 pm
長音記号ですらなくなっています... AIでの変換でもないのでこの変換はまずいのでは。
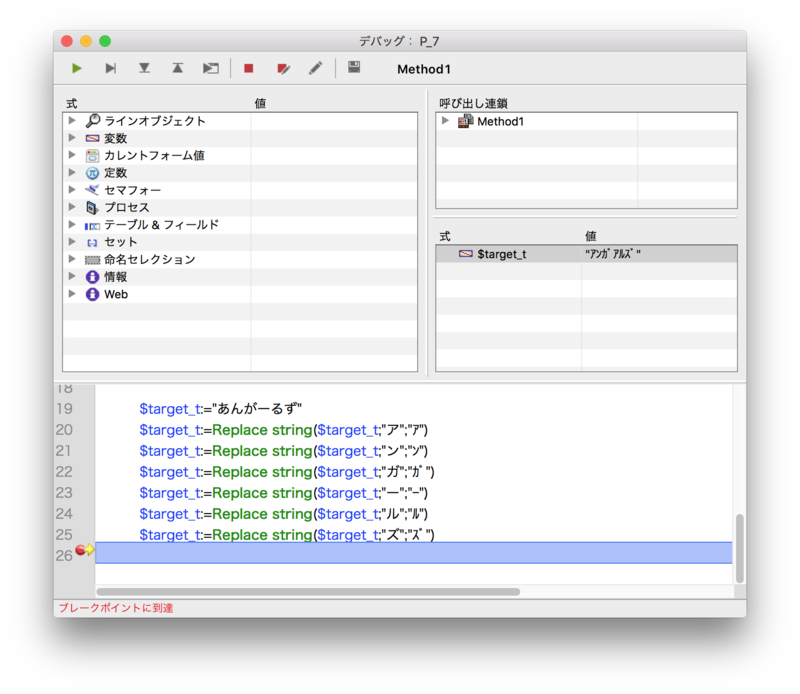
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by miyako 2018-04-25, 2:13 pm
by miyako 2018-04-25, 2:13 pm
「あー」=「ああ」(sort order=default, standard, traditional)
と基本的に同じことが起きています。
$src:="あんがーるず"
$dst:=$src
$dst:=Replace string($dst;"ア";"ア") //アんがアるず
・・・と,最初の置換で「あー」=「ああ」が働いています。
(この場合は「がー」=「があ」)
Unicodeの標準(v11の初期・v16の現状)では,「ー」を単独の記号ではなく,直前の音を伸ばす母音と同一であるとみなす,という判定です。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by hosaka 2018-04-25, 2:21 pm
by hosaka 2018-04-25, 2:21 pm
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by miyako 2018-04-25, 2:31 pm
by miyako 2018-04-25, 2:31 pm
はい,まったく同感です。(これを避けるためにv11.5でsort order=tranditionalを採用したわけですから・・)
望まれるような振る舞いにできるよう,引き続き努めてゆきたいと思います。
最終編集者 miyako [ 2018-04-25, 5:17 pm ], 編集回数 1 回
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by hosaka 2018-04-25, 2:52 pm
by hosaka 2018-04-25, 2:52 pm
プログラミングしている者としては、基本的にReplace string(*)の指定と動作が逆な方がよいのではないかと考えます。
標準が文字コードに基づいた評価、*オプションがICUに基づく評価
ついでにL2もしくはL3などコレーションが指定できるとか、変換元文字列に正規表現が記載できるとかしてもらえると助かります。
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by 内山 高志 2018-05-14, 1:51 am
by 内山 高志 2018-05-14, 1:51 am
(色々追われてまして..)
文字コード回りは色々やっかいですね。
以前、v11で問題があった時は、4Dでパッチを当てたのではなく、ICUのオブジョンの指定を変えたのですね。
hosakaさんのご提案の通り、色々デベロッパで指定できるのは助かります。
できる事が広がりますので。
基本は今までと同じ動作で、その気になれば細かくも指定できる。が、私としては一番ありがたいです。
検証大変だと思いますけど、よろしくお願いします。
内山 高志- 投稿数 : 37
登録日 : 2016/07/13
Re: 長音記号とReplace string
![]() by miyako 2018-05-31, 10:33 pm
by miyako 2018-05-31, 10:33 pm
建設的なご意見ほんとうにありがとうござました。
miyako- 投稿数 : 483
登録日 : 2016/07/05
Re: 長音記号とReplace string
![]() by hosaka 2018-06-05, 2:39 pm
by hosaka 2018-06-05, 2:39 pm
二日ほど頑張ってみたのですがダメでした。なにか良い方法はないでしょうか?
なのでまだ未確認です。
hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by hosaka 2018-06-07, 10:00 am
by hosaka 2018-06-07, 10:00 am
直っていないみたいです。どの様な修正が施されたのかご説明をお願いします。

hosaka- 投稿数 : 241
登録日 : 2016/07/04
所在地 : 大阪
Re: 長音記号とReplace string
![]() by osaru 2018-06-09, 10:52 am
by osaru 2018-06-09, 10:52 am
hosaka wrote:確認してみました。v16.3 224148です。
直っていないみたいです。どの様な修正が施されたのかご説明をお願いします。
4D v16.3 Hotfix 4でバグフィックスリストに載っていました。すこしテストしてみましたけど修正されているみたいですね。
ACI0098157 Since ICU50, prolonged sound mark ("-") is no longer considered as a letter when the DB language is set to Japanese.
当方macOS Sierra(10.12.6) 4D v16.3 Hotfix 4 64bit環境ですが、Windowsだと状況がまた異なるのでしょうか?
不思議なのは、バージョンが4D v16.3 build 16.224100 64-bitと上記より番号が若くなっていました・・・
osaru- 投稿数 : 67
登録日 : 2017/08/14
Page 1 of 2 • 1, 2 ![]()
|
|
|